Quick answer: evaluate RAG in layers. Measure retrieval recall and precision, reranking and context quality, answer groundedness and faithfulness, citation accuracy and usefulness, refusal and no-answer behavior, permissions and security, latency and cost, freshness, and user outcome metrics. Do not rely on one blended score.
Start with golden query datasets that include expected source IDs, answer boundaries, no-answer cases, exact identifiers, domain terms, follow-ups, and multilingual phrasing. Then run repeatable offline tests, human annotation, regression checks, and online feedback loops after launch.
MythyaVerse treats production RAG as grounded knowledge infrastructure: document preparation, metadata strategy, hybrid retrieval, reranking, grounded generation, evaluation, monitoring, and secure deployment for enterprise and government constraints.

9
metric layers
Retrieval, reranking, grounding, citations, refusal, permissions, freshness, cost, and outcome metrics answer different questions.
Top-k
source recall
The expected passage, source ID, or record should appear before the model is asked to write.
Human
annotation
Domain review remains essential for policy, education, finance, healthcare, government, and regulated enterprise use cases.
Core idea
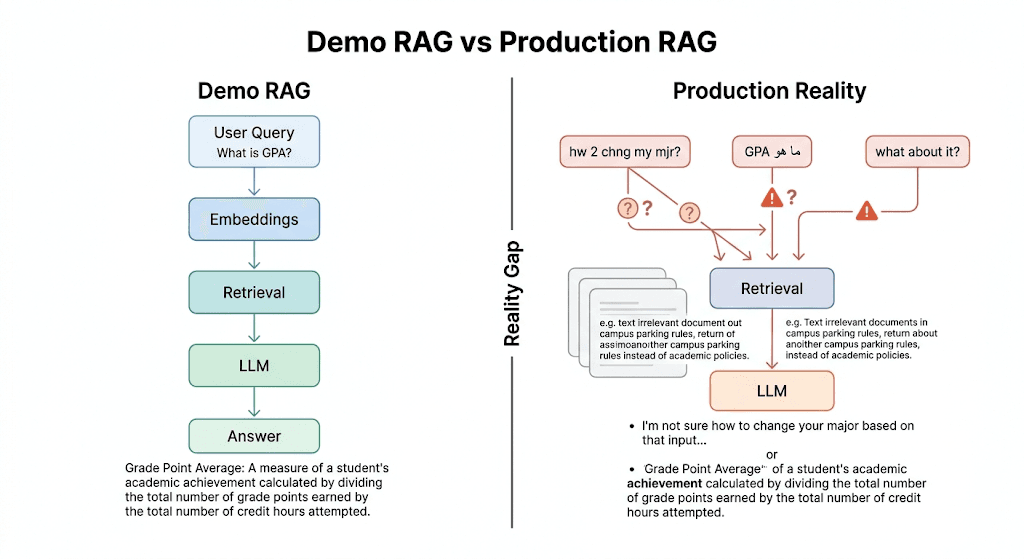
Evaluate the RAG pipeline layer by layer because a polished answer can hide a broken retrieval path, weak context, unsupported claims, bad citations, or a missing refusal.
Service
RAG Development Company
Enterprise retrieval, hybrid search, grounding, evaluation, observability, and secure deployment.
OpenArticle
18 Hidden RAG Mistakes
A deeper production guide to the failure modes that appear after a clean RAG demo.
OpenCase study
MOSD Oman Policy Assistant
A multilingual government RAG assistant with accessibility support and on-prem deployment.
OpenCase study
Extramarks Teaching Deck
An education RAG and generation workflow grounded in curriculum content.
OpenRetrieval and Context
Measure top-k recall, precision, context noise, reranking behavior, and exact-source coverage.
6 retrieval checks
Grounding and Citations
Check faithfulness, unsupported claims, source attribution, citation usefulness, and refusal behavior.
6 answer checks
Security and Ops
Track permission leaks, prompt injection, freshness, latency, cost, feedback, and regression risk.
8 production checks
Planning Decisions
Quick Answer: Metrics to Use Before and After Launch
RAG quality cannot be measured by answer vibes or a single average score. The useful metric set tells the team where failure starts and what engineering response is needed.
Use the same framework before launch, during vendor evaluation, and after deployment because documents, users, permissions, and workflows change.
Create golden queries with expected source IDs
Decision
Build a dataset of representative questions with expected document IDs, passage IDs, accepted answer boundaries, language requirements, permission assumptions, and no-answer cases.
Why it matters
Without expected sources, teams cannot tell whether a good-looking answer was grounded in the right evidence or produced from weak context.
Practical move
Include common questions, rare edge cases, ambiguous follow-ups, exact IDs, policy numbers, domain terms, multilingual phrasing, conflicting sources, and questions the system should refuse.
Measure retrieval recall, precision, and context noise
Decision
Track whether the expected source appears in top-k candidates, whether irrelevant chunks crowd out the context window, and whether metadata filters preserve the right source version.
Why it matters
If retrieval fails, the model may still write a fluent answer that distracts from the real issue. If retrieval is noisy, the model may blend weak evidence into a plausible but unreliable response.
Practical move
Measure top-k retrieval recall, context precision, context relevance, context entity recall where useful, and failure tags by source type, query type, language, permission group, and freshness state.
Check reranking and context assembly
Decision
Evaluate whether reranking promotes the best passage, removes duplicates, respects source status, and keeps the final context compact enough for grounded generation.
Why it matters
Many production failures happen after first retrieval: the right passage is found but not selected, buried under noise, mixed with stale material, or trimmed away before generation.
Practical move
Review reranker wins and losses, final-context composition, duplicate chunks, source diversity, conflicting passages, exact-ID matches, and metadata-filter behavior before changing the prompt.
Score groundedness, faithfulness, and citations separately
Decision
Review whether each answer is supported by selected evidence, avoids unsupported claims, cites the sources it actually used, and gives users enough citation detail to verify the response.
Why it matters
A correct-looking answer with fake, vague, or decorative citations is not production-ready for enterprise RAG, especially when auditability matters.
Practical move
Score answer faithfulness, groundedness, answer accuracy, citation accuracy, citation usefulness, unsupported claims, missing caveats, and source-attribution quality as separate labels.
Evaluate refusal, no-answer, permissions, and security
Decision
Test whether the system refuses unsupported questions, avoids permission leaks, handles hidden prompt-injection attempts in source documents, and routes sensitive failures to review.
Why it matters
Enterprise RAG should not answer every question. It should know when evidence is missing, stale, unauthorized, contradictory, or unsafe to use.
Practical move
Create no-answer and refusal datasets, permission leak tests, role-based source checks, prompt-injection tests, source-conflict examples, and reviewer escalation paths.
Track freshness, latency, cost, and user outcomes online
Decision
Monitor ingestion lag, stale sources, unresolved intents, user feedback, human corrections, latency, cost per answer, retrieval failures, model failures, and repeated low-confidence topics.
Why it matters
A RAG system can degrade even when the model and prompt do not change because documents, access rules, language mix, and user behavior change after launch.
Practical move
Connect logs, traces, feedback, source IDs, and annotation queues so each recurring failure can be traced to content, retrieval, reranking, generation, permissions, or product workflow.
Use evaluation tools as helpers, not final judges
Decision
Evaluation platforms and libraries can organize datasets, traces, evaluator runs, human feedback, and metric categories, but they do not replace domain review or product judgment.
Why it matters
Tools can make evaluation repeatable, but a metric name is not proof that the answer is safe, useful, current, or allowed for a specific user.
Practical move
Treat LangSmith, Ragas, TruLens, and similar tooling as examples of evaluation and tracing categories. Calibrate automated evaluators against human annotation and keep production decisions tied to business risk.
Operating Model
A Useful RAG Evaluation Stack
Evaluation should be designed as part of the product, not as a one-time QA spreadsheet.
A practical stack tests indexing, retrieval, reranking, generation, citations, refusal, security, and live usage separately, then ties failures back to the right owner.
Golden query and source registry
Collect representative questions with expected source IDs, answer boundaries, no-answer labels, roles, languages, and document-version assumptions.
Where it helps
Gives the team a repeatable baseline for retrieval recall, citation accuracy, refusal correctness, multilingual behavior, and regression testing.
Offline retrieval and reranking tests
Score top-k recall, context precision, context noise, entity recall, metadata filters, reranker behavior, and final-context composition before generation.
Where it helps
Shows whether failures start in indexing, chunking, query rewriting, hybrid retrieval, permissions, reranking, or context assembly.
Answer, citation, and no-answer review
Evaluate groundedness, faithfulness, unsupported claims, citation accuracy, citation usefulness, answer completeness, refusal correctness, and escalation behavior.
Where it helps
Keeps answer quality aligned with policy, curriculum, support, government, legal, or operational reality instead of generic fluency.
Permission and security test suite
Run permission leak tests, prompt-injection tests, sensitive-source checks, tenant or role isolation checks, and log/export access checks.
Where it helps
Prevents a source-grounded assistant from becoming an unauthorized data disclosure path.
Human annotation and regression loop
Let domain reviewers label failures, approve improved behavior, compare experiment runs, and rerun the same datasets after corpus, prompt, model, or retrieval changes.
Where it helps
Turns evaluation into a maintainable improvement loop instead of a one-off launch gate.
Online monitoring and outcome metrics
Track live failures, latency, cost, stale content, unresolved intents, source coverage, user feedback, task completion, escalation rates, and correction rates.
Where it helps
Shows when the knowledge system starts drifting after launch and whether it improves real work, not only benchmark scores.
Practical Checklist
RAG Metrics Checklist
Use this list to keep RAG evaluation practical, diagnosable, and tied to production behavior.
Keep this in mind
RAG evaluation is valuable only when it points to an engineering response: improve documents, metadata, chunking, retrieval, reranking, answer policy, citations, refusals, permissions, or monitoring.
The goal is not a perfect benchmark or one blended score. The goal is a grounded knowledge system that gets easier to improve every week and remains safe as sources, users, and deployment constraints change.
Work With MythyaVerse
Building a knowledge system that has to answer from trusted sources?
We design RAG systems around retrieval quality, grounding, multilingual behavior, evaluation, and secure deployment rather than demo-only chat.
Continue Reading
Related articles
18 Hidden Mistakes That Keep Your RAG System Stuck in Demo Mode
What looks reliable in a clean demo often collapses under real traffic. This article maps the failure modes that appear in production RAG and the system design needed to handle them.

Best RAG Development Companies for Enterprise Knowledge Systems
The best RAG partner depends on whether you need custom implementation, enterprise deployment, document parsing, vector search, observability, or managed cloud RAG.

RAG vs Fine-Tuning for Enterprise Knowledge Assistants: Which Should You Use?
Use RAG for changing, source-grounded company knowledge. Consider fine-tuning or model optimization for repeated behavior, style, schemas, and task patterns.