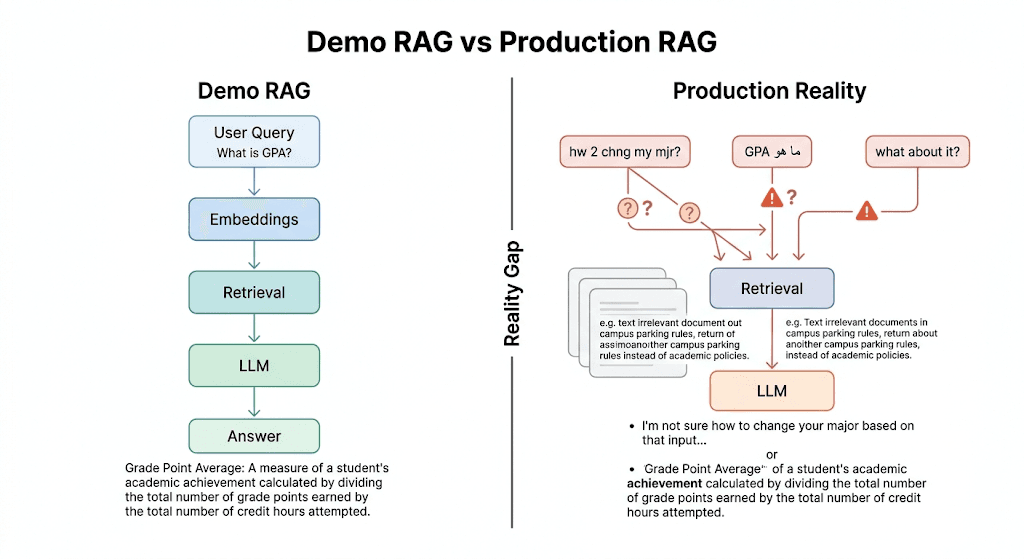
The first version of a RAG system usually feels deceptively strong. You index a small document set, retrieve the top matches, pass them to an LLM, and the result sounds grounded, useful, and ready to ship.
That confidence rarely survives contact with real users. Production traffic arrives with vague follow-ups, mixed-language prompts, shorthand, typos, urgency, and expectations of perfect consistency. What looked like a single pipeline becomes a systems problem.
This article is not a primer on how RAG works. It is a production lens on where RAG fails, why those failures keep repeating, and what architecture decisions turn a promising demo into a dependable product.
18
failure modes
The recurring issues that surface once real users replace your clean test prompts.
5
diagnostic layers
Input understanding, retrieval, grounding, user experience, and system reliability.
1
production mindset
Design for the unhappy path first, then optimize the happy path for speed.
Core idea
A RAG system that works in a demo proves the concept. A RAG system that survives production proves the system design.
Service
RAG Development Company
Explore how MythyaVerse designs enterprise retrieval pipelines, grounding, evaluation, and secure deployment.
OpenCase study
MOSD Oman bilingual policy assistant
A government RAG case study with Arabic-English access, accessibility support, and on-prem deployment.
OpenCase study
Extramarks teaching deck generator
An EdTech content workflow grounded in curriculum material and platform integration.
OpenInput Understanding
Messy queries, ambiguity, context loss, and multi-part asks.
4 recurring issues
Retrieval Quality
Exact terms, semantics, ranking, and language nuance.
4 recurring issues
Generation & Grounding
Hallucinations, weak citation, and polluted context windows.
3 recurring issues
User Experience
Intent mismatch, poor tone, and no emotional awareness.
4 recurring issues
System Reliability
Provider failures, malformed output, and stale knowledge bases.
3 recurring issues
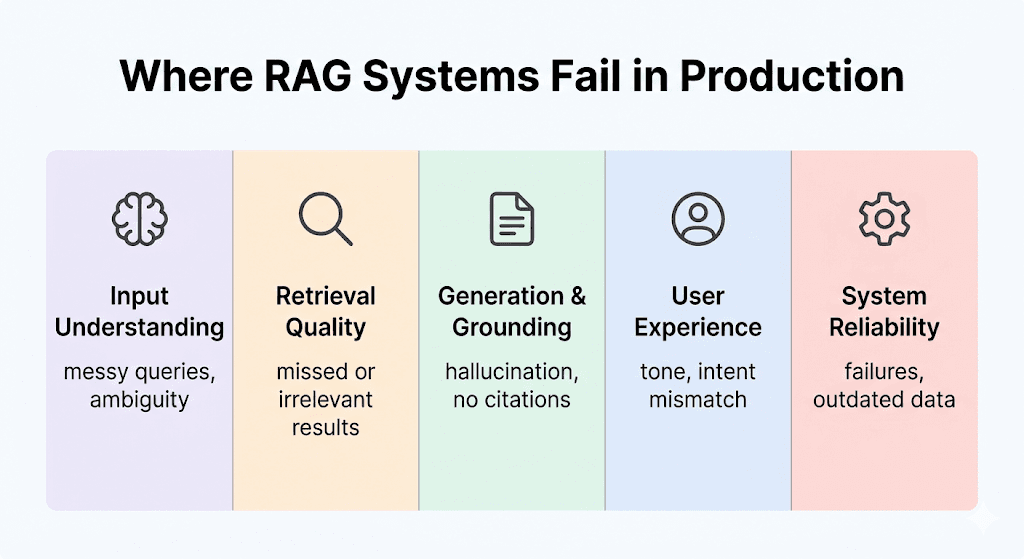
Input Understanding
The Query Is Usually the First Production Failure
Most RAG systems assume the user will express their need clearly, in one language, with enough context to retrieve the answer directly. That assumption holds in internal testing because the team already knows how the system is supposed to be used.
Real users do not collaborate with your architecture. They ask follow-ups, combine requests, switch languages mid-sentence, and compress intent into shorthand. Unless the system explicitly interprets the message before retrieval begins, failure starts before search even happens.
Ambiguous Language Detection
Example: "ما هو GPA"
What breaks
Mixed-language queries such as "ما هو GPA" look simple to a human but create inconsistent routing and response language selection in a naive pipeline.
Why it matters
If the system cannot deterministically identify how to interpret the prompt, answer quality becomes unstable. In multilingual products, inconsistency is a trust problem, not just a UX inconvenience.
Design response
Detect language explicitly before retrieval, preserve mixed tokens like GPA or course codes, and route the normalized query with an explicit response-language instruction downstream.
Context-Free Follow-Ups
Example: "What are the requirements for Summer Semester Exemption?" followed by "What about it?"
What breaks
A user asks a valid first question, receives a good answer, and then follows up with "What about it?" or "And how long does that take?" without repeating the subject.
Why it matters
The second query often fails not because knowledge is missing, but because the referent is gone. Retrieval sees a fragment while the user assumes the system remembers the conversation state.
Design response
Introduce conversation memory plus query rewriting that resolves pronouns and short follow-ups into a self-contained retrieval query before search begins.
Multi-Part Questions
Example: "What are the transcript fees and how long does it take?"
What breaks
Users routinely bundle related requests into one line, like asking for fees, timelines, and eligibility in a single message.
Why it matters
One retrieval pass usually over-indexes on one part of the question and under-serves the rest, so the answer sounds polished while still being incomplete.
Design response
Break compound questions into atomic sub-questions, retrieve independently for each one, and synthesize the response in a single structured answer.
Messy, Real-World Input
Example: "hw 2 chng my mjr?"
What breaks
Production traffic is full of shorthand, typos, abbreviations, and emotionally compressed messages that look nothing like QA test prompts.
Why it matters
Embeddings and lexical search both degrade when the system treats raw noisy text as the final query representation.
Design response
Normalize spelling, expand abbreviations, preserve a clean rewritten query for retrieval, and keep the original input for auditability and debugging.
Retrieval Quality
Search Quality Breaks Long Before Generation Does
A large share of apparent hallucination is really retrieval failure in disguise. The model can only ground itself in what reaches the context window, and search quality determines that upstream.
Production search has to respect exact identifiers, broad meaning, ranking precision, and language nuance at the same time. A single retrieval strategy rarely handles all of those requirements well.
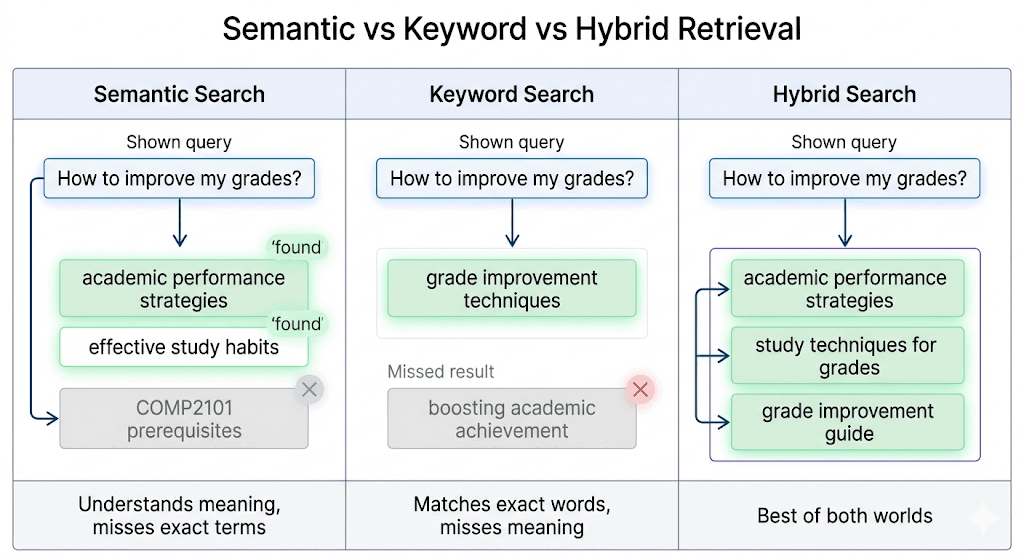
Semantic Search Misses Exact Matches
Example: "What are the prerequisites for COMP2101?"
What breaks
Dense retrieval understands broad meaning well, but it can miss critical literal identifiers such as course codes, invoice numbers, or policy IDs.
Why it matters
If a user asks for COMP2101 and the system only retrieves conceptually similar study guidance, the answer can sound relevant while still being factually useless.
Design response
Blend semantic retrieval with lexical matching and boost exact identifiers, product names, part numbers, and policy references during ranking.
Keyword Search Misses Meaning
Example: "How do I improve my grades?" versus "GPA enhancement strategies"
What breaks
Sparse retrieval excels at exact words but breaks when users phrase the same idea differently from the source content.
Why it matters
A search system that only honors literal overlap will miss the document even when the human meaning is obviously the same.
Design response
Use hybrid retrieval so semantic search recovers concept matches while lexical search protects exact business terms and entity names.
One-Size-Fits-All Embeddings
What breaks
A single multilingual embedding model is convenient, but it often smooths over nuance and weakens retrieval quality for specific languages or domains.
Why it matters
The degradation is subtle, which makes it hard to diagnose. Teams often accept "good enough" search while non-English users silently receive worse answers.
Design response
Evaluate language-specific or domain-tuned embeddings, and measure retrieval quality separately for each user segment instead of relying on one blended average.
Initial Ranking Errors
What breaks
Even when the right document is retrieved somewhere in the top 50, it may never reach the model if first-pass ranking leaves it too low.
Why it matters
Generation quality depends on the final five or ten chunks, not the hidden long list you never send to the LLM.
Design response
Retrieve broadly, rerank aggressively around the final intent, and make room for exact-match signals and high-confidence metadata before truncating context.
Generation & Grounding
Grounding Fails When the Model Has Too Much Freedom
Once context reaches the model, many teams assume the hard work is over. It is not. Generation still has to stay grounded, transparent, and resilient to imperfect retrieval.
The key failure mode here is not that the model is unintelligent. It is that it tries to be helpful even when the retrieved material is incomplete, noisy, or contradicted by prior knowledge.
Hallucination from Prior Knowledge
What breaks
LLMs arrive with general background knowledge that may conflict with your institution-specific or product-specific policies.
Why it matters
Without strict grounding, the model blends retrieved context with what it "already knows," producing answers that feel credible while drifting away from your actual source of truth.
Design response
Use tightly constrained prompts, cite supporting passages, and instruct the model to abstain or qualify when the retrieved context is insufficient.
Lack of Source Attribution
What breaks
Many RAG answers look good but provide no citation trail for the user or the team reviewing failures later.
Why it matters
Without source visibility, users cannot validate the answer and the product team cannot debug whether the issue came from retrieval, ranking, or generation.
Design response
Attach chunk-level references to the final answer and make source attribution a first-class output requirement instead of a nice-to-have.
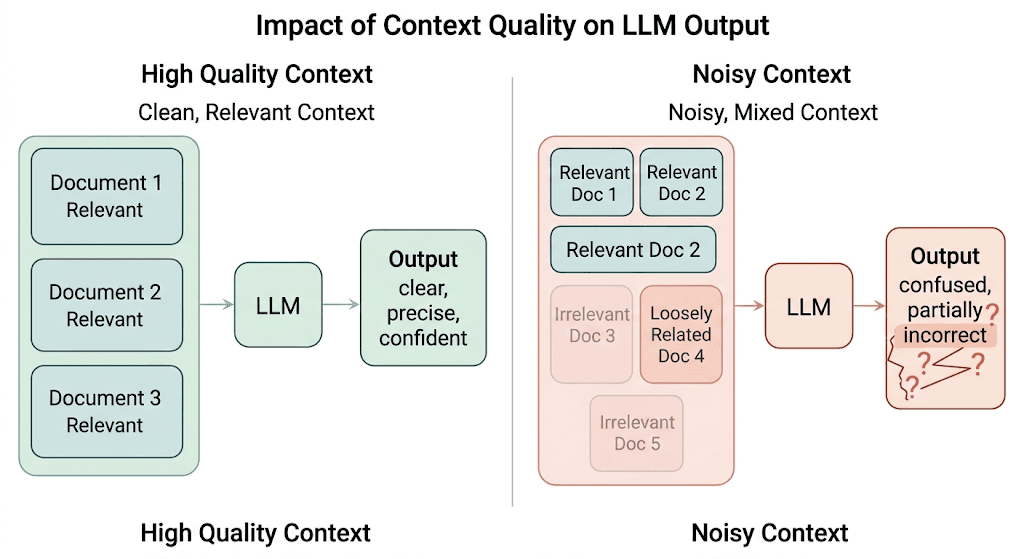
Noisy Context
What breaks
If the final context window contains a few good chunks and a few loosely relevant ones, the model still tries to use all of them.
Why it matters
That creates diluted, hedged, or internally inconsistent responses. The issue is not always too little context. Sometimes it is too much weak context.
Design response
Prune aggressively after reranking, deduplicate semantically similar chunks, and favor fewer highly relevant passages over a broad but noisy bundle.
User Experience
A Correct Answer Can Still Feel Like a Product Failure
Production systems are judged on interaction quality as much as on raw factual accuracy. Users notice tone, urgency, clarity, and whether the system understood what they were trying to do.
This is where many technically competent RAG systems still disappoint. They answer the words on the screen while missing the human state behind the request.
Ignoring User Emotion
Example: "I've emailed three times about my transcript. This is urgent."
What breaks
Messages that communicate stress or urgency are often handled with the same neutral tone used for ordinary information requests.
Why it matters
A user saying they have emailed three times about an urgent document is signaling more than a search need. A flat response feels tone-deaf even if it is factually correct.
Design response
Run sentiment or urgency detection before generation so the system can adapt tone, acknowledge the situation, and escalate faster when appropriate.
No Scope Awareness
Example: "What's the weather today?" in a policy assistant
What breaks
A general-purpose chatbot instinctively answers everything, even when a request is outside the knowledge base or outside product scope.
Why it matters
Users would rather receive a clear boundary than a confident answer assembled from irrelevant context.
Design response
Classify whether the query belongs in the RAG system at all, and respond with a graceful out-of-scope message or alternate route when it does not.
Missing Intent Differentiation
Example: "How do I book a room?" versus "Book a room for me."
What breaks
Informational prompts and action requests are often treated as the same task even though they require different system behavior.
Why it matters
A user asking how to book a room needs guidance. A user asking the system to book the room needs workflow execution or a handoff. Conflating the two creates friction immediately.
Design response
Separate informational, transactional, and escalation intents early so the response path matches what the user is actually trying to achieve.
One-Size-Fits-All Tone
What breaks
A system that always sounds the same eventually feels robotic, especially in high-stakes or stressful contexts.
Why it matters
Tone is part of reliability. If the interaction style is mismatched to the user's state, the product feels brittle even when retrieval and generation are technically correct.
Design response
Define tone policies by intent and urgency level, then let the generation stage adapt wording while keeping factual content stable.
System Reliability
Production RAG Is Also an Operations Problem
Once a RAG system depends on external APIs, vector stores, rerankers, and content pipelines, reliability stops being a model-only problem. It becomes distributed systems engineering.
This layer is often ignored in prototypes because the happy path hides it. In production, every missing fallback, malformed payload, or stale index shows up directly in the user experience.
Single Points of Failure
What breaks
A modern pipeline frequently depends on multiple external services: embeddings, vector search, rerankers, moderation, generation, and storage.
Why it matters
If any one of those dependencies fails and there is no fallback path, your "AI product" becomes unavailable even though most of the system still works.
Design response
Add degraded-mode behavior, provider fallbacks, cached responses for common requests, and clear monitoring so one failing component does not collapse the whole chain.
Unreliable Output Formats
What breaks
Even well-prompted models occasionally emit malformed JSON or drift from the schema your downstream code expects.
Why it matters
A single parsing error can turn an otherwise correct response into a product outage or broken UI state.
Design response
Validate outputs, retry with repair prompts when formatting fails, and avoid brittle assumptions that one model response will always match the schema perfectly.
Outdated Knowledge Bases
What breaks
RAG systems can sound highly authoritative while answering from stale policies, old documentation, or incomplete indexes.
Why it matters
This is one of the most dangerous failure modes because the output may look correct to everyone until the user acts on outdated information.
Design response
Treat content freshness as part of the architecture: version documents, monitor ingestion lag, and expose last-updated signals where users and operators can see them.
From Demo to Deployment
A Production-Ready RAG Stack Is Multi-Stage by Design
The deeper pattern across all eighteen issues is simple: basic RAG is optimized for the happy path. Production traffic lives in the unhappy path.
That is why a single-shot embed-retrieve-generate loop stops being enough. Each new stage in a production architecture exists to resolve a specific class of failure before it propagates downstream.
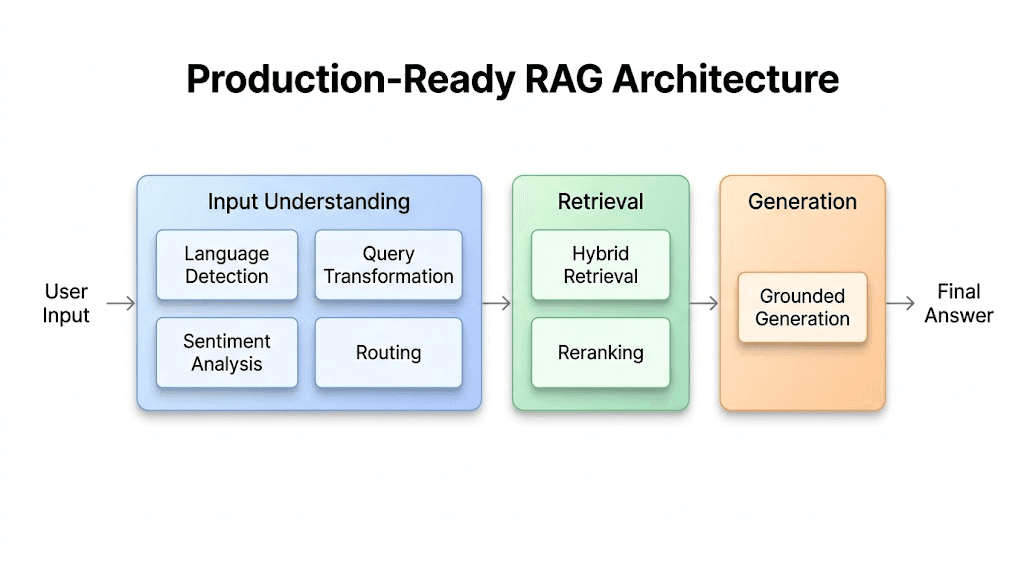
Language Detection
Decide how the system should interpret the message and what language the answer should use.
Why it exists
Fixes mixed-language ambiguity and prevents inconsistent responses for multilingual users.
Query Transformation
Rewrite follow-ups, clean noise, expand abbreviations, and split compound questions into retrievable units.
Why it exists
Fixes context-free follow-ups, messy text, and incomplete retrieval for bundled requests.
Sentiment Analysis
Detect urgency, frustration, or user stress before the generation stage chooses tone and escalation strategy.
Why it exists
Fixes emotionally tone-deaf answers and helps the product respond proportionally to urgency.
Routing
Classify whether the request belongs in the knowledge base, needs an action workflow, or should be treated as out of scope.
Why it exists
Fixes intent confusion and prevents irrelevant generation for requests the system should not answer.
Hybrid Retrieval
Combine semantic search with lexical matching so meaning and exact terms both survive the retrieval stage.
Why it exists
Fixes the trade-off where semantic search misses identifiers and keyword search misses meaning.
Reranking
Re-order retrieved candidates around final user intent before context is trimmed for the model.
Why it exists
Fixes first-pass ranking errors and reduces noisy, low-value context from entering generation.
Grounded Generation
Generate only from curated evidence, with citation and refusal behavior when the evidence is weak.
Why it exists
Fixes hallucination, weak transparency, and answers that overstate confidence despite missing support.
Final Thought
Better Models Help, but Better Systems Win
The biggest misconception in RAG is that a stronger model will automatically fix production behavior. It usually will not.
The real leap is architectural discipline: understanding the query correctly, retrieving with the right mix of recall and precision, grounding the answer tightly, and keeping the surrounding system operational when parts fail.
Keep this in mind
When a RAG system is designed for the unhappy path, it stops feeling like a clever feature and starts behaving like infrastructure.
That shift is what turns retrieval-augmented generation from a demo pattern into a dependable product capability.
Work With MythyaVerse
Designing a RAG system that has to survive real traffic?
We help teams move from retrieval demos to production systems with better query handling, retrieval quality, grounding, and deployment discipline.
Continue Reading
Related articles

RAG Evaluation Metrics That Actually Matter in Production
Evaluate RAG layer by layer, not with one blended score: retrieval, context quality, grounded answers, citations, refusal behavior, permissions, freshness, cost, and outcomes.

Best RAG Development Companies for Enterprise Knowledge Systems
The best RAG partner depends on whether you need custom implementation, enterprise deployment, document parsing, vector search, observability, or managed cloud RAG.

RAG vs Fine-Tuning for Enterprise Knowledge Assistants: Which Should You Use?
Use RAG for changing, source-grounded company knowledge. Consider fine-tuning or model optimization for repeated behavior, style, schemas, and task patterns.